

















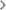


1、MongoDB查询优化器
1)MongoDB查询优化器会选择最优的一条执行计划来执行SQL。
2)查询优化器会缓存那些有多条可用索引的SQL的执行计划条目
2、查询优化器原理
1)对于每个SQL,查询优化器会先在在执行计划缓存中查找执行计划
2)如果没有匹配到相应的执行计划,查询优化器会生成备选执行计划,并评估他们各自的消耗,选择中最佳执行计划,并将23)这些执行计划放入缓存中
3)MongoDB根据最优执行计划返回结果
4)如果匹配到可用的执行计划,MongoDB会通过replanning的机制再次评估当前执行计划的性能
5)如果评估成功,使用该执行计划返回结果
6)如果评估失败,查询优化器重复2)操作,最终选择最优执行计划返回结果

3、执行计划缓存刷新机制
1)删除集合或者索引会重新刷新执行计划缓存
2)执行计划缓存在MongoDB重启后会失效
3)MongoDB2.6版本之后可以执行db.collection.getPlanCache().clear()手动刷新执行计划缓存
1、语法
方法一:
db.collection.find().explain()
查看help帮助文档:
db.collection.explain().help()
?
方法二:
db.collection.explain().find()
查看help帮助文档:
db.collection.explain().find().help()
?
2、执行计划的三种模式
queryPlanner Mode:只会显示 winning plan 的 queryPlanner,自建MongoDB默认模式
executionStats Mode:只会显示 winning plan 的 queryPlanner + executionStats
allPlansExecution Mode:会显示所有执行计划的 queryPlanner + executionStats,阿里云MongoDB默认模式
?
不论哪种模式下,查看一个SQL的执行计划,都是通过查询优化器来判断的,对于所有写操作,查询执行计划只会限制起操作的消耗,不会执行操作进行变更。
3、Mongodb 执行计划解析
MongoDB执行计划主要分为两个部分:queryPlanner、executionStats
?
示例集合:
db.asir.find().limit(1).pretty()
{
"_id" : ObjectId("5d3954a3cd19f9203957cea4"),
"id" : 0,
"name" : "sakw",
"age" : 18,
"date" : ISODate("2019-07-25T07:05:07.695Z")
}db.asir.createIndex({age:1})
db.asir.createIndex({name:1,age:1})
?
示例查询:
db.asir.find({name:"aa",age:{$gte:28},date:ISODate("2019-07-25T07:05:07.695Z")}).explain("executionStats")
?
1、queryPlanner
queryPlanner主要有三大部分:parsedQuery、winningPlan、rejectedPlans。
我们关注比较多的是winningPlan,查看SQL当前执行走了什么索引
?
1)parsedQuery - SQL解析
该部分解析了SQL的所有过滤条件
?
2)winningPlan - SQL最终选择的执行计划
winningPlan可以分三部分来看:stage、filter、inputStage
?
3)rejectedPlans - 被淘汰的执行计划
?
2、executionStats
最好的情况是:nReturned=totalKeysExamined=totalDocsExamined
?
3、serverInfo 服务器信息
阿里云MonogoDB实例上其实将这个信息隐藏掉了。
?
4、indexFilterSet
?
indexFilter仅仅决定对于该查询MongoDB可选择的索引是由什么决定的。若indexFilterSet为true,说明该查询只能选择indexFilter设置的一些可选索引,最终选择使用哪个索引由优化器决定;若indexFilterSet=false,说明该查询可以选择该集合所有的索引,最终选择使用哪个索引由优化器确定。
?
1)如何设置indexFilter
db.runCommand(
? {
planCacheSetFilter: <collection>, ? //需要创建indexFilter集合
query: <query>, //指定哪类查询使用indexFilter
sort: <sort>, //排序条件
projection: <projection>, //查询字段
indexes: [ <index1>, <index2>, ...]? //indexFilter可使用索引
? }
)
?
2)如何删除indexFilter
db.runCommand(
? {
planCacheClearFilters: <collection>, //指定集合
query: <query pattern>, //指定查询类别
sort: <sort specification>, //排序条件
projection: <projection specification> //查询字段
? }
)
?
3)如何查看一个集合所有的indexFilter
db.runCommand( { planCacheListFilters: <collection> } )
?
4)示例:
?
集合数据如下:
db.scores.find()
{ "_id" : ObjectId("523b6e32fb408eea0eec2647"), "userid" : "newbie" }
{ "_id" : ObjectId("523b6e61fb408eea0eec2648"), "userid" : "abby", "score" : 82 }
{ "_id" : ObjectId("523b6e6ffb408eea0eec2649"), "userid" : "nina", "score" : 90 }
{ "_id" : ObjectId("5d303213cd8afaa592e23990"), "userid" : "AAAAAAA", "score" : 43 }
{ "_id" : ObjectId("5d303213cd8afaa592e23991"), "userid" : "BBBBBBB", "score" : 34 }
{ "_id" : ObjectId("5d303213cd8afaa592e23992"), "userid" : "CCCCCCC" }
{ "_id" : ObjectId("5d303213cd8afaa592e23993"), "userid" : "DDDDDDD" }db.scores.createIndex({userid:1,score:1})
?
创建indexFilter:
?
查看执行计划:
?
5)注意点
?当使用index filter的时候,使用hint强制走index filter之外的索引会失效,
4、stage类型
stage的类型:
COLLSCAN:全表扫描
IXSCAN:索引扫描
FETCH:根据索引去检索指定document
SHARD_MERGE:将各个分片返回数据进行merge
SORT:表明在内存中进行了排序
LIMIT:使用limit限制返回数
SKIP:使用skip进行跳过
IDHACK:针对_id进行查询
SHARDING_FILTER:通过mongos对分片数据进行查询
COUNT:利用db.coll.explain().count()之类进行count运算
COUNTSCAN:count不使用Index进行count时的stage返回
COUNT_SCAN:count使用了Index进行count时的stage返回
SUBPLA:未使用到索引的$or查询的stage返回
TEXT:使用全文索引进行查询时候的stage返回
PROJECTION:限定返回字段时候stage的返回
?
对于普通查询,我希望看到stage的组合(查询的时候尽可能用上索引):
Fetch+IDHACK
Fetch+ixscan
Limit+(Fetch+ixscan)
PROJECTION+ixscan
SHARDING_FITER+ixscan
COUNT_SCAN
?
如下的stage效率比较低下:
COLLSCAN(全表扫描)
SORT(使用sort但是无index)
SUBPLA(未用到index的$or)
COUNTSCAN(不使用index进行count)
1、对于当前正在发生的情况
1)查看当前会话情况,抓取正在慢的SQL
重点关注:
2)查看问题SQL执行计划
2、对于历史问题
1)查看慢日志以及运行日志
如何调整慢日志参数:
慢日志参数解释:
查看慢日志信息:
2)查看问题SQL执行计划
1、查询优化
1)建立合适索引
?1.在选择性较好的字段建立索引
?2.单列索引不需要考虑升降序,但是复合索引可以根据业务需求创建对应升降序的复合索引
?3.覆盖索引查询,查询和过滤的所有字段都在复合索引中
2)使用limit限定返回结果,减轻网络开销
3)需要哪些字段查询哪些字段
4)使用hint强制走指定索引
?
2、写操作优化
1)集合上的索引会增加该集合写入/更新操作的资源消耗,适度创建索引
MMAPv1存储引擎中,当一个update操作所需要的空间超过了原本分配的空间时,MMAPv1存储引会将该文档移动到磁盘上一个新的位置,并全部将该集合的索引进行更新指向新的文档位置,整个过程是非常消耗资源的。
从MongoDB 3.0开始,MonogoDB使用 Power of 2 Sized Allocations,保证MongoDB尽量对空间的空间重用,尽量减少重新分配空间位置的发生。
2)硬件优化,固态SSD的性能要优于HDDs
3)合理设置journal相关参数
?1.journal日志实现日志预写功能,开启journal保证了数据的持久化,但也存在一定的性能消耗
?2.尽量将数据文件与journal日志文件放在不同的磁盘喜爱,避免I/O资源争用,提高写操作能力
?3.j:true参数会增加写操作的负载,根据业务实际情况合理使用write concern参数
?4.设置合理的commitIntervalMs参数
减小该参数会减少日志提交的时间间隔、增加写操作的数量,但是会限制MongoDB写能力。
增大该参数会增加日志提交的时间间隔、减少写操作的数量,但是增加了MongoDB意外宕机期间日志没有落盘的可能。





